Density of 1000 F0 contours
A Prompt-based Text-To-Speech model allows a user to control different aspects of speech,
such as speaking rate and perceived gender, through natural language instruction. Although user-friendly,
such approaches are on one hand constrained: control is limited to acoustic features learned by the model
during training, and too flexible on the other: the same inputs yields uncontrollable variation that are
reflected in the corpus statistics.
We investigate a novel fine-tuning regime to address both of these issues at the same time by exploiting
the uncontrollable variance of the model. Through principal component analysis of thousands of synthesised
samples, we determine latent features that account for the highest proportion of the output variance and
incorporate them as new labels for secondary fine-tuning. We evaluate the proposed methods on two models
trained on an expressive Icelandic speech corpus, one with emotional disclosure and one without. In the
case of the model without emotional disclosure, the method yields both continuous and discrete features
that improve overall controllability of the model.
We make all model checkpoints available on HuggingFace. EmotiveIcelandic corresponds to T3-emotional in our paper. The RepeatTTS series of models corresponds to the different fine-tuned versions of T3 in our paper. Follow installation instructions on HF to setup the models.
All our datasets are based on an emotional Icelandic open-source corpus, with the addition of descriptive prompts for every utterance. talromur3 with prompts includes information about the rendered emotion, while talromur3 without emotions does not.
We prompt Mistral-7B-Instruct-v0.2 to generate the description prompts used for training our models. Here is the full prompt used to train T3-emotional.
You will be given 7 descriptive keywords related to an audio sample of [speaker_name]'s speech. These keywords include:
1. The gender (male, female)
2. The level of reverberation (very distant-sounding, distant-sounding, slightly distant-sounding, slightly close-sounding, very close-sounding)
3. The amount of noise in the sample (extremely noisy, very noisy, noisy, slightly noisy, almost no noise, very clear)
4. The tone of the speaker's voice (very monotone, monotone, slightly expressive and animated, expressive and animated, very expressive and animated)
5. The pace of the speaker's delivery (very slowly, slowly, slightly slowly, moderate speed, slightly fast, fast, very fast)
6. The pitch of the speaker's voice (very low-pitch, low-pitch, slightly low-pitch, moderate pitch, slightly high-pitch, high-pitch, very high-pitch)
7. The emotion of the speaker's voice. This could be one of 6: Happy, Sad, Angry, Surprised, Helpful or Neutral.
This will also include the intensity of the emotion (for example:
- neutral emotion: there is no particular emotion
- high intensity sad emotion: the speaker is sad and the intensity of the emotion is high
- medium intensity happy emotion: the speaker sounds happy and the intensity of that emotion is medium
- low intensity surprised emotion: the speaker sounds a little bit surprised
- very high intensity helpful emotion: the speaker sounds incredibly helpful
...)
Your task is to create a text description using these keywords that accurately describes the speech sample.
If the amount of noise is 'very noisy' and the level of reverberation is 'very distant-sounding', you must include terms such as 'very poor recording' or `very bad recording` in the description.
Likewise, if the amount of noise is 'very clear' and the level of reverberation is 'very close-sounding', you must include terms like 'very good recording' or `excellent recording` in the description.
And you must always specify what the emotion of the speaker is, and the intensity of that emotion. For example, if the emotion of the speaker is "low intensity happy emotion", you must include terms like `slightly happy sounding` in the description.
Do not add extra details beyond what has been provided above. You can change the order of keywords, and replace synonymous terms.
For example, given the following keywords: 'female', 'slightly distant-sounding', 'noisy', 'very expressive and animated', 'very slowly', 'moderate pitch' and 'high intensity angry emotion' a valid description would be: '[speaker_name] speaks very slowly but has a very animated delivery. She sounds noticably angry. The recording is noisy and there is some roominess.'
Another valid description would be: 'In a noisy room, [speaker_name] delivers a very animated and expressive speech, at a very slow pace. [speaker_name] is audibly angry.'
Another valid description would be: '[speaker_name] enunciates a very expressive speech while clearly angry. Her voice is slightly distant-sounding, with some background noise present. [speaker_name] speaks very slowly with a moderate pitch but a very expressive tone.'
Note that the intensity of the speaker's emotion is sometimes specifically mentioned. This should not be confused with the speaker's tone. So, for example: the speaker might
be 'very expressive and animated' and have 'low intensity sad emotion'. In which case you have to describe the tone of voice as being expressive (e.g. '[speaker_name]'s tone is highly dynamic') while the intensity of the emotion is low (e.g. '[speaker_name] sounds a little bit sad')
Ensure that the generated description is grammatically correct, easy to understand, and concise. Only return one and only one description.
For the keywords: '[gender]', '[reverberation]', '[sdr_noise]', '[speech_monotony]', '[speaking_rate]', '[pitch]' and '[emotion]' the corresponding description is:
These samples are generated using T3-emotional. We synthesise the same text for all speakers and emotions. The emotional intensity is set to 3 of 5, so in each case the model is prompted with, e.g. "[speaker]'s voice sounds clear and close to the microphone. The [speaker] sounds [emotion]."
Emotional intensity labels are included in the training prompts for T3-emotional, which allow the model to synthesise emotions on a 5 point scale. This is done by prompting the model with, e.g. "The speaker's voice sounds clear and close to the microphone. The [speaker] sounds [intensity] [emotion]" where [intensity] can be, for example, "extremely", "somewhat", "slightly" etc.
These samples are generated using T3. This model was trained on instruction prompts without any information about emotional content. In this case, the prompts are: "[speaker] sounds very clear and close to the microphone.". The model output is more varied than for T3-emotional since the model is still trained on emotional data without disclosure of the labels.
These samples are generated using T3 Level 2. This model has been further fine-tuned on a single speaker (Ingrid) subset of Talromur with labels discovered from the output distribution. These labels roughly correspond to three different levels of vocal intensity. In this case, the prompts are: "Ingrid sounds very clear and close to the microphone. [intensity information].", where [intensity information] can be empty or "Ingrid's voice is at [medium/high] intensity"
These samples are generated using T3 Level 3. This model has been further fine-tuned from Level 2 with the addition of a neutral speaking label, discovered from the output distribution of T3 level 2. "Ingrid sounds very clear and close to the microphone. [label].", where [label] can be "Ingrid's voice is neutral." or "Ingrid's voice is at [low/high] intensity."
We performed a simple grid search over the hyperparameters k (for k-sampling) and t (for temperature) to determine a suitable configuration for expressive and varied generation.
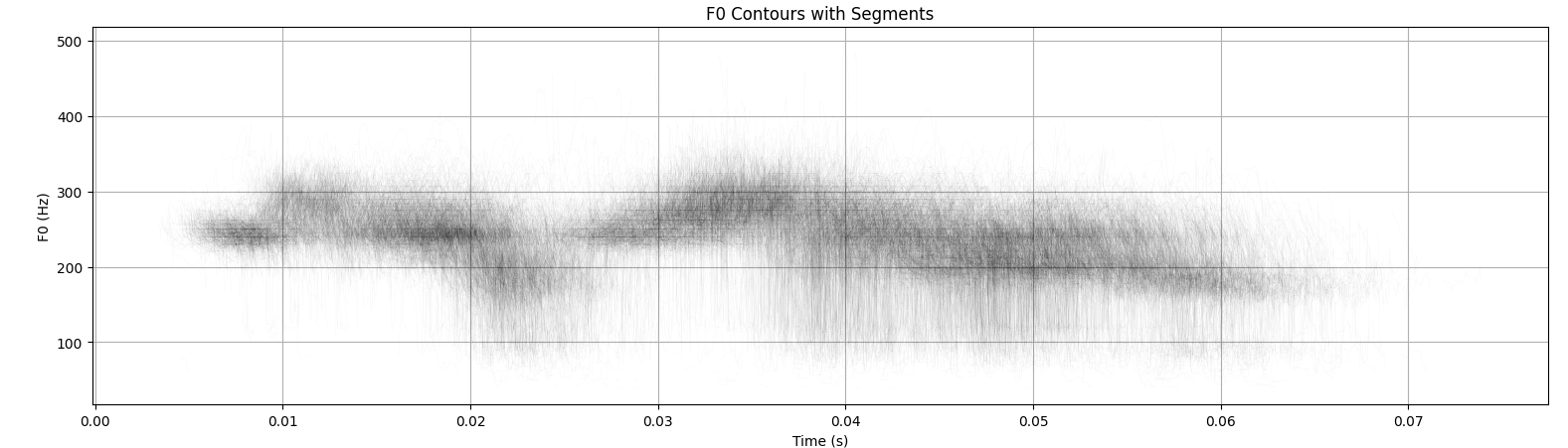
With default generation parameters, the model is highly consistent for fixed inputs. The figure below shows an overlay of 1,000 generated samples in a neutral speaking test, and the corresponding overlayed audio.
Density of 1000 F0 contours
Prompting the model with ambiguous speaker labels, such as the man, the woman or the person, sometimes yields voices that are distinct from the training voices.